
Важные новости


Важные новости


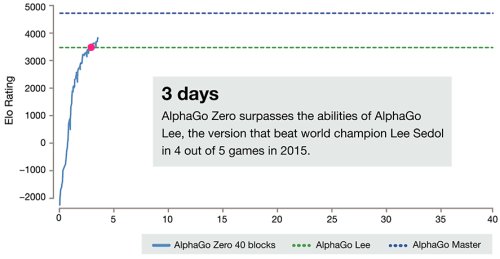
Более мощная версия программы AlphaGo самостоятельно достигла уровня совершенства всего за три дня

В течение нынешнего и прошлого года программа AlphaGo, построенная на принципах искусственного интеллекта, одержала ряд выдающихся побед над высококвалифицированными игроками в древнюю китайскую игру Го, включая и чемпиона мира Ли Седоля (Lee Sedol). И не так давно представители DeepMind, подразделения компании Google, занимающегося разработкой систем искусственного интеллекта, представили новый и более мощный вариант программы - AlphaGo Zero. Во время тестовых испытаний новая программа обыграла свой предыдущий вариант, тот, который в свое время одержал победу над Ли Седолем, абсолютно "всухую", с невероятным счетом 100:0.
Напомним нашим читателям, что оригинальный вариант программы AlphaGo получил первоначальный опыт, проанализировав около 160 тысяч матчей, сыгранных в онлайн-режиме живыми людьми, членами всемирной ассоциации игры Го. После этого начального обучения программа AlphaGo начала играть сама с собой и миллионы таких "внутренних" матчей позволили ей поднять мастерство игры на недостижимый для людей уровень.
Новая система AlphaGo Zero уже не нуждается даже в первоначальных человеческих знаниях, процесс ее обучения основан только на механизме игры самой с собой. В самом начале самообучения программа делала первые шаги (ходы) абсолютно произвольно и случайно, запоминая те комбинации, которые ведут к победе и поражению. И за 29 миллионов таких игр, сыгранных самой с собой всего за три дня, система AlphaGo Zero стала самым лучшим игроком на земном шаре.
Система AlphaGo Zero более проста и более "умна", нежели система предыдущего поколения. В состав оригинальной программы входили два независимых обучающихся и самообучающихся модуля, построенные на базе искусственных нейронных сетей. Один модуль отвечал за оценку текущей ситуации на игровой доске, а второй - искал все доступные варианты следующего хода. И третий модуль выбирали из найденных вариантов следующего хода только те, которые соответствуют выбранной стратегии текущего матча и ведут к победе. Система AlphaGo Zero является еще более лучшим игроком за счет того, что у этой системы имеется единая мощная нейронная сеть, которая одновременно анализирует положение на доске и выбирает следующий ход при помощи более простого модуль поиска по нескольким критериям.
И в заключение следует отметить, что некоторые идеи, воплощенные в жизнь специалистами DeepMind при создании системы AlphaGo, были использованы компанией Google в практических целях. Благодаря работе искусственного интеллекта компании удалось существенно сократить расходы на охлаждение информационных центров, а общая сумма прибыли, полученной всеми отделами компании Alphabet, составила уже порядка 40 миллионов фунтов стерлингов. Более того, алгоритмы, лежащие в основе новой системы AlphaGo Zero, могут быть достаточно легко адаптированы для решения множества проблем научного и технического плана, к примеру, для разработки новых лекарственных препаратов, конструкционных материалов и всего другого, где необходимо делать качественный выбор их "математического океана" всех возможных вариантов решений.
 Политика «Зеленський пояснив, чому зараз неможливо повернути Крим та вступити до НАТО»
Политика «Зеленський пояснив, чому зараз неможливо повернути Крим та вступити до НАТО»  Общество «Справа про переслідування адвоката Дениса Федоркіна українськими правоохоронцями отримала нове життя після втручання іспанського суду»
Общество «Справа про переслідування адвоката Дениса Федоркіна українськими правоохоронцями отримала нове життя після втручання іспанського суду»  Политика «Питання про території має вирішувати народ через вибори чи референдум, – Зеленський»
Политика «Питання про території має вирішувати народ через вибори чи референдум, – Зеленський»  Мир «У Болгарії через протести громадян уряд пішов у відставку»
Мир «У Болгарії через протести громадян уряд пішов у відставку»  Мир «Поліція Польщі затримала російського вченого, підозрюваного в нищенні спадщини Криму»
Мир «Поліція Польщі затримала російського вченого, підозрюваного в нищенні спадщини Криму»  Политика «Якщо ЗАЕС залишиться за росіянами - вона не буде працювати, – Зеленський»
Политика «Якщо ЗАЕС залишиться за росіянами - вона не буде працювати, – Зеленський»